Parsing XML file data in APEX

If you are a web developer then chances are that you must have used XML. In fact, even non developers have heard about it. It has been a general format for storing, sending and receiving data in the software Industry. Even with other format like JSON slowly taking it’s own place for getting the same job done, XML still works as the only method for many API response. We can simply generate and parse XML file to contain data.
Different platforms give us their own way of generating and parsing XML, and likewise APEX is no exception. Any Salesforce developer who is working with external API calls must have encountered the problem of parsing an XML file, at some point in their career.
Now if we look at an XML file it seems like all jumbled up data which is hardly readable by human eyes, let alone a machine. How can we code to parse an XML file? Well the data is not as much jumbled as you think and even parsing an XML file in APEX is not too complex of a task. Let’s see how can we parse XML with the predefined classes of APEX.
Dummy XML data
First thing first, we’ll be needing XML data to parse, so let’s take some dummy XML data.
<?xml version="1.0" encoding="UTF-8"?>
<products>
<product>
<name>Xbox</name>
<code>XBO</code>
</product>
<product>
<name>Playstation</name>
<code>PS</code>
</product>
<product>
<name>Wii</name>
</product>
</products>In the above XML data we can see that there are various tags. The first tag being an XML tag. This tag tells that the document is an XML document. Moving on we have products, which is a root tag. Every XML document has only one root tag. Next we have multiple product tags, which shows that this is carrying an array of products.
Each array has it’s own child nodes, name and code. The data filled in one product tag is the data of that product in the array and each child node corresponds to the label of the data it is carrying. This brings us to the actual data, which is stored in the tags.
APEX Code
public class XMLparse{
/**
* Webkul Software.
*
* @category Webkul
* @author Webkul
* @copyright Copyright (c) 2010-2017 Webkul Software Private Limited (https://webkul.com)
* @license https://store.webkul.com/license.html
**/
string XMLString;
public list pro;
product2 temppro;
public XMLparse(){
pro = new list();
XMLString = '<?xml version="1.0" encoding="UTF-8"?><products><product><name>Xbox</name><code>XBO</code></product><product><name>Playstation</name><code>PS</code></product><product><name>Wii</name></product></products>';
DOM.Document doc=new DOM.Document();
try{
doc.load(XMLString);
DOM.XmlNode rootNode=doc.getRootElement();
parseXML(rootNode);
pro.add(temppro);
insert pro;
}catch(exception e){
system.debug(e.getMessage());
}
}
private void parseXML(DOM.XMLNode node) {
if (node.getNodeType() == DOM.XMLNodeType.ELEMENT) {
system.debug(node.getName());
if(node.getName()=='product'){
if(temppro!=null)
pro.add(temppro);
temppro = new product2();
}
if(node.getName()=='name')
temppro.name=node.getText().trim();
if(node.getName()=='code')
temppro.productcode=node.getText().trim();
}
for (Dom.XMLNode child: node.getChildElements()) {
parseXML(child);
}
}
}In the above class we can see that there are two functions, one constructor to the class and the other which actually parses the XML data. The XML string is fed to the DOM.Document class object which construct a document object for this XML class. Once it is dome we are going to get the root element of the XML file with the help of getRootElement function of DOM.Document class and feed it to the XmlNode class object.
This node object will become an argument for the parseXML function and hence we are going to call that function to initiate the main part. The getName() function will return the name of the element like, <name> will return name while the node.getText() function will return the content of that tag.
node.getChildElelement() will return all the child elements of a tag. The return type of getText() function is string so the data will always be in string format. If you want to convert it to any other type you can use the valueOf function of that class.
After the successful execution of this class the control will return to the constructor and it will call the insert command.
Output
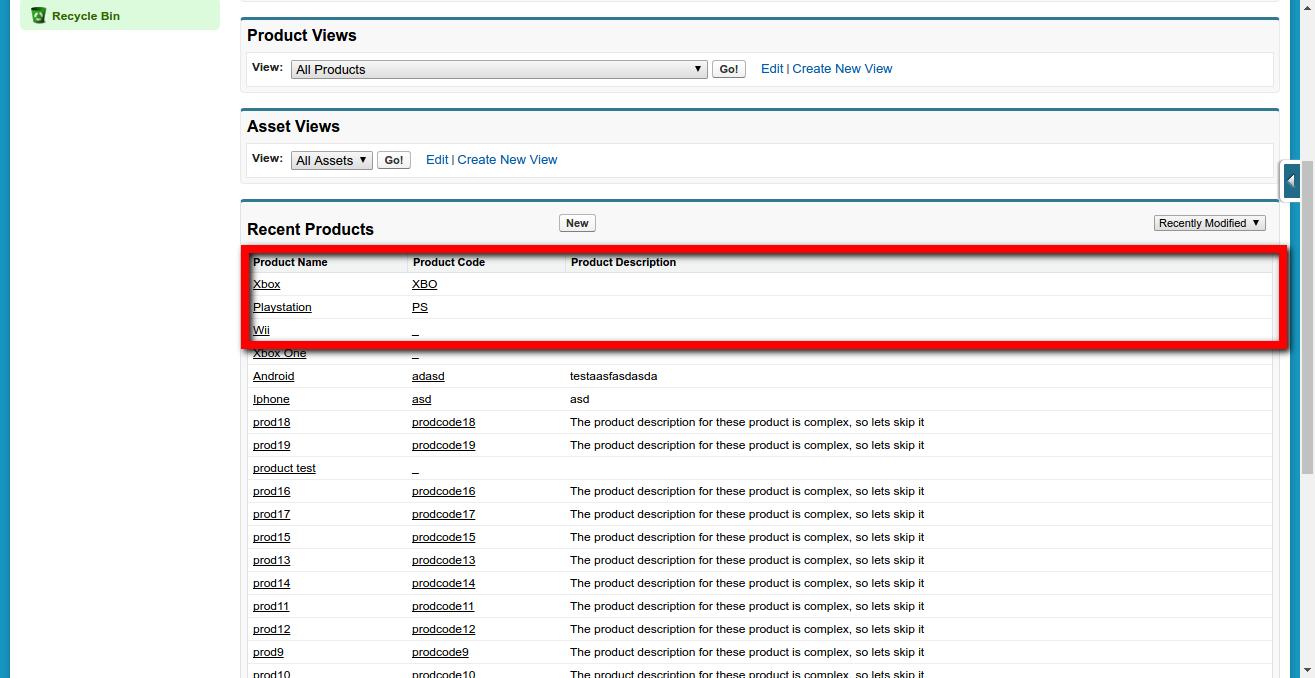
To test this class you can either create a VF page and add the controller of that VF page as this class, or you can simply create an object of this class in Anonymous Window from Developer Console. Soon after you will do this the updates will be visible to you in products as three new products will be added from the XML data.
Here I have executed the code via the Anonymous Window from Developer Console and the result was:
SUPPORT
That’s all for how parse XML data in Apex, for any further queries feel free to contact us at:
https://wedgecommerce.com/contact-us/
Or let us know your views on how to make this code better, in comments section below.